Setting Up a Web Enabled Lending Library
Setting Up a Web Enabled Lending Library
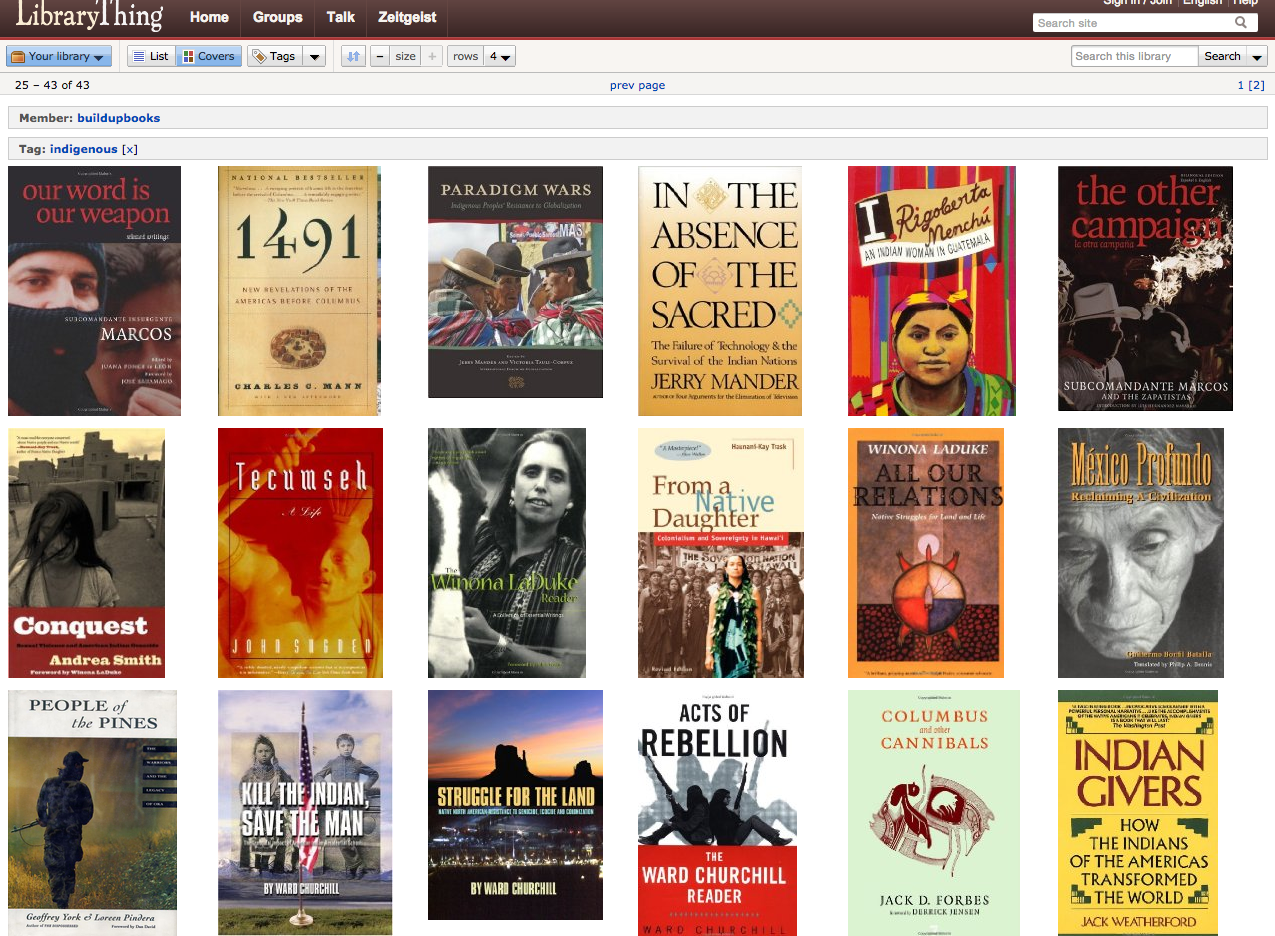
I started cataloging books for a small community center's lending library at librarything.com. Librarything.com is a great web site that I highly recommend. If most of your books have ISBNs and you can borrow someone's barcode scanner, cataloging books at Librarything is a snap: on the "add books page" you scan a books ISBN and all of its information (Title, Author, book cover) will be added by Librarything for you. Of course if you don't have a bar code scanner or there is no ISBN, you simply type in part of the title or author and select the book from a list of possible matches, this is a bit slower, but perfectly adequate if you are inputting a smaller library.
Once all of the books are added, the social networking goodness begins! You're library has its own mini-site at Librarything, with a publicly available catalog: Build Up Books catalog and profile: Build Up Books profile. So for a community center, you can send out the URL, and anyone can search the catalog for books they find of interest.
The one problem with this system, is there isn't a robust system for checking out books. Some libraries have adapted an informal system of tagging books as "checked out" and in the private comments (only visible to the administrator) added the borrowers contact information. This is somewhat acceptable, but first: you would have to give any volunteers access to all of your Librarything account's permissions (you get all or nothing as far admin rights goes on Librarything). Second there is no way to tell when the book was checked out, when it is due back, and also no way to sort by which books are currently overdue. So I thought I would look into importing the library, once cataloged, into a drupal web site.
Exporting Library from Librarything
Librarything has excellent importing and exporting facilities. To export, sign in to your account and then go to http://librarything.com/more/import. On that page there are links for downloading your catalog as either a comma separated csv file or a tab delimited text file.
Downloading User Uploaded Book Covers
Librarything has over 1,000,000 user uploaded book covers, and it makes them available for free. You need to a developer's key to access them and there are some restrictions: you can only download 1000 per day and one per second. So with these understandable restrictions, I decided it would be best to download the book covers and store them locally. So yesterday I wrote a python script to download all of the book covers for our library.
The Python Script
I will add a link at the bottom to the script on my Github Repository. So the script I wrote searches through a librarything csv file, finds all of the ISBNs and downloads the book covers from Librarything.
import re, urllib, csv,time
CSV_FILE ='~/Downloads/LibraryThing_export.csv'
IMG_DIR ='~/img/'
DEV_KEY = 'YOUR_LIBRARYTHING_DEV_KEY'
IMG_URL = "http://covers.librarything.com/devkey/" + DEV_KEY + "/large/isbn/"I use 4 python libraries.
- Re: for regular expressions to search for isbns.
- urllib: for downloading the Book Cover from Librarything
- csv: for creating a map data structure from a parsed csv file.
- time: for limiting the downloads to one per second.
Also I add a couple of variables. The important one to change is DEV_KEY which contains your librarything developers key. Also make sure the CSV_FILE points at your downloaded CSV_FILE and the IMG_DIR exists. Finally IMG_URL points to the web service on librarything where you can download user submitted book covers, all you need to do is slap an ISBN on the end of that URL and the URL will return either a book cover, or a clear 1x1 gif if they do not have that cover.
# read in the Librarything Export File
lt_dict = csv.DictReader(open(CSV_FILE))
#loop through the rows of the dictionary
for row in lt_dict:
# grab the ISBN dictionary field
mystr = row["'ISBN'"]
# search for a matching ISBN
mymatch = re.match(r"\[(\d+)\]",mystr)
# if no match, print the title to STDOUT
if mymatch is None:
print "blank isbn for: %s" % row["'TITLE'"]
else:
# grab the matching string, this is our ISBN!
isbn = mymatch.group(1)
# build the web service request URL
myurl = IMG_URL + isbn
# where we will store the downloaded Book cover image
myfile = "%slarge_%s" % (IMG_DIR,isbn)
# urlretrieve downloads the image and stores it locally
urllib.urlretrieve(myurl,myfile)
print "myurl: %s, myfile: %s" % (myurl,myfile)
# sleep for 2 seconds
time.sleep(2)The hard work is done by csv.DictReader and urllib.urlretrieve. DictReader takes a csv file, parses the first line of the file for field names and creates a dictionary data type, so you can loop through the rows and have access to the fields by name. Urlretrieve, takes a URL and an optional file name and it grabs the file at the URL and stores it locally as the filename you provided.
In a later blog post I will describe the Drupal end of this project: creating a book CCK content type, importing data into Drupal custom content types, and setting up the check out process.